Visual Effects
Using nerfies you can create fun visual effects. This Dolly zoom effect would be impossible without nerfies since it would require going through a wall.
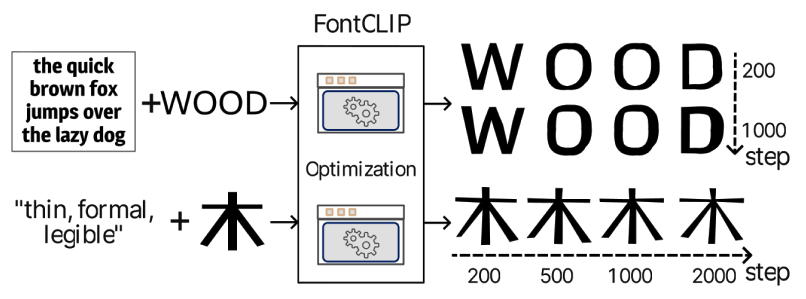
Authentic human handwriting inherently possesses rich variations, and these subtle differences endow the text with vitality and realism. However, when text is digitized into computer fonts, identical characters appear rigid and monotonous, entirely losing the natural fluctuations of handwriting. To break the limitations of digital typography, this research explores a handwriting generation framework based on Vision-Language Models (VLMs), aiming to guide standard computer fonts to produce natural variations with handwritten characteristics.
This method leverages the cross-modal semantic understanding capabilities of VLMs (such as FontCLIP) to drive font deformation. Nevertheless, during the research process, it was discovered that directly applying existing models often leads to excessive deformation, resulting in the collapse of core structures and the critical issue of "losing the essence of the original font." To resolve this technical bottleneck, this study introduces fine-grained local feature control and rigorous evaluation mechanisms into the generation framework, specifically implementing quantitative testing for deformations in key structures, such as the lower components of the characters.
By combining the visual feature space with local structural constraints, the proposed model successfully preserves the core essence of the reference font while simultaneously endowing it with diverse handwritten characteristics. Experimental results indicate that, under strict evaluation metrics for local deformation, our method effectively mitigates the distortion defects observed in baseline models. This research not only successfully extends standard computer fonts into the domain of highly variable handwriting but also provides an innovative solution for future personalized font synthesis and emotion-driven text generation.
Using nerfies you can create fun visual effects. This Dolly zoom effect would be impossible without nerfies since it would require going through a wall.
As a byproduct of our method, we can also solve the matting problem by ignoring samples that fall outside of a bounding box during rendering.
We can also animate the scene by interpolating the deformation latent codes of two input frames. Use the slider here to linearly interpolate between the left frame and the right frame.
Start Frame
End Frame
Using Nerfies, you can re-render a video from a novel viewpoint such as a stabilized camera by playing back the training deformations.
There's a lot of excellent work that was introduced around the same time as ours.
Progressive Encoding for Neural Optimization introduces an idea similar to our windowed position encoding for coarse-to-fine optimization.
D-NeRF and NR-NeRF both use deformation fields to model non-rigid scenes.
Some works model videos with a NeRF by directly modulating the density, such as Video-NeRF, NSFF, and DyNeRF
There are probably many more by the time you are reading this. Check out Frank Dellart's survey on recent NeRF papers, and Yen-Chen Lin's curated list of NeRF papers.
@article{park2021nerfies,
author = {Park, Keunhong and Sinha, Utkarsh and Barron, Jonathan T. and Bouaziz, Sofien and Goldman, Dan B and Seitz, Steven M. and Martin-Brualla, Ricardo},
title = {Nerfies: Deformable Neural Radiance Fields},
journal = {ICCV},
year = {2021},
}